Com a exploração de paralelismo e o consequente crescimento exponencial de desempenho nas últimas décadas, a fabricação de multiprocessor chips (CMP) é cada vez mais complexa. Multiprocessadores requerem modos de comunicação entre seus núcleos. Arquiteturas baseadas em trocas de mensagem fornecem ao processador uma memória local que só pode ser acessada por ele e requer trocas de mensagens com os demais núcleos do sistema. Arquiteturas baseadas em memória compartilhada fazem com que toda a memória seja acessível por todos os núcleos, possibilitanto a comunicação através de loads e stores. A abstração de uma única memória compartilhada requer um modelo conceitual de operações de memória que podem ser executadas simultaneamente de forma a orientar o programador sobre uma ordem específica de comportamento de programas paralelos.
Esse modelo, implementado em hardware, é chamado de Memory Consistency Model (MCM). Na busca cada vez maior de aumento de desempenho, fabricantes de multicore chips passaram a utilizar MCM’s cada vez mais relaxados, onde instruções de leitura e escrita podem ser realizadas fora da ordem especificada pelas threads de um programa. O aumento de número de núcleos de processamento e o uso de modelos de consistência relaxados corroboram o aumento da complexidade de projetos de processadores, deixando-os sucetíveis a erros.
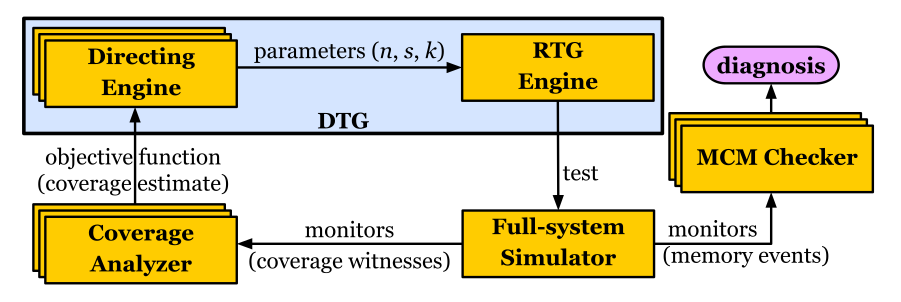
A verificação funcional, essencialmente, é um processo comparativo entre o que o processador idealmente deveria ser e o que ele atualmente é. No contexto de CMPs, o processo de verificação consiste em executar programas concorrentes em simuladores de multicores chips e avaliar se o comportamento observado corresponde ao comportamento esperado. Tais programas são criados automaticamente através de agentes inteligentes e o comportamento do MCM do(s) chip(s) também é automaticamente avaliado por checkers depois (post-morten) ou durante a execução (on-the-fly).
O ECL, durante mais de uma década de pesquisa, desenvolveu um complexo, porém eficiente framework de verificação funcional de memória compartilhada. O Framework consiste de gerador automático de programas concorrentes, um checker e agentes inteligentes que direcionam a criação automática de testes, de forma a diminuir o tempo e o esforço de verificação, explorando as características desse problema. Cada programa concorrente é executado em um multicore, estimulando o sistema de memória compartilhada. O checker verifica automaticamente se, ao executar o programa, algum comportamento observado desobedeceu o modelo de memória do multicore, o que representa um erro no hardware.
Após mais de uma década de publicações, o grupo de testes em multicore do ECL continua trabalhando na geração automática de testes, de forma a reduzir o tempo e o esforço de verificação, criando novas formas de representação de testes e algoritmos inteligentes. Além de portar o framework para Instruction Set Architectures para SPARC e ARM, o RISC-V surge como um alvo de portabilidade e publicações.
A partir dessa área de pesquisa, o ECL produziu teses de doutorado, dissertações de mestrado e projetos de iniciação científica, gerando publicações de alto impacto científico e profissionais qualificados que trabalham com pesquisas no Brasil e em empresas na Europa e nos Estados Unidos da América.
Publicações (até 2023):
E. A. Rambo, O. P. Henschel and L. C. V. dos Santos, “Automatic generation of memory consistency tests for chip multiprocessing,” 2011 18th IEEE International Conference on Electronics, Circuits, and Systems, Beirut, Lebanon, 2011, pp. 542-545, doi: 10.1109/ICECS.2011.6122332.
L. S. Freitas, G. A. G. Andrade and L. C. V. dos Santos, “Efficient verification of out-of-order behaviors with relaxed scoreboards,” 2012 IEEE 30th International Conference on Computer Design (ICCD), Montreal, QC, Canada, 2012, pp. 510-511, doi: 10.1109/ICCD.2012.6378698.
E. A. Rambo, O. P. Henschel and L. C. V. dos Santos, “On ESL verification of memory consistency for system-on-chip multiprocessing,” 2012 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 2012, pp. 9-14, doi: 10.1109/DATE.2012.6176424.
L. S. Freitas, G. A. G. Andrade and L. C. V. dos Santos, “A template for the construction of efficient checkers with full verification guarantees,” 2012 19th IEEE International Conference on Electronics, Circuits, and Systems (ICECS 2012), Seville, Spain, 2012, pp. 280-283, doi: 10.1109/ICECS.2012.6463746.
L. S. Freitas, E. A. Rambo and L. C. V. dos Santos, “On-the-fly verification of memory consistency with concurrent relaxed scoreboards,” 2013 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 2013, pp. 631-636, doi: 10.7873/DATE.2013.138.
O. P. Henschel and L. C. V. dos Santos, “Pre-silicon verification of multiprocessor SoCs: The case for on-the-fly coherence/consistency checking,” 2013 IEEE 20th International Conference on Electronics, Circuits, and Systems (ICECS), Abu Dhabi, United Arab Emirates, 2013, pp. 843-846, doi: 10.1109/ICECS.2013.6815546
G. A. G. Andrade, M. Graf and L. C. V. dos Santos, “Chain-based pseudorandom tests for pre-silicon verification of CMP memory systems,” 2016 IEEE 34th International Conference on Computer Design (ICCD), Scottsdale, AZ, USA, 2016, pp. 552-559, doi: 10.1109/ICCD.2016.7753340.
G. A. G. Andrade, M. Graf, N. Pfeifer and L. C. V. dos Santos, “Steep Coverage-Ascent Directed Test Generation for Shared-Memory Verification of Multicore Chips,” 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 2018, pp. 1-8, doi: 10.1145/3240765.3240852.
G. A. G. Andrade, M. Graf and L. C. V. dos Santos, “Chaining and Biasing: Test Generation Techniques for Shared-Memory Verification,” in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 39, no. 3, pp. 728-741, March 2020, doi: 10.1109/TCAD.2019.2894376.
M. Graf, O. P. Henschel, R. P. Alevato and L. C. V. dos Santos, “Spec&Check: An Approach to the Building of Shared-Memory Runtime Checkers for Multicore Chip Design Verification,” 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 2019, pp. 1-7, doi: 10.1109/ICCAD45719.2019.8942040.
G. A. G. Andrade, M. Graf, N. Pfeifer and L. C. V. dos Santos, “A Directed Test Generator for Shared-Memory Verification of Multicore Chip Designs,” in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 39, no. 12, pp. 5295-5303, Dec. 2020, doi: 10.1109/TCAD.2020.2974343.
N. Pfeifer, B. V. Zimpel, G. A. G. Andrade and L. C. V. dos Santos, “A Reinforcement Learning Approach to Directed Test Generation for Shared Memory Verification,” 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 2020, pp. 538-543, doi: 10.23919/DATE48585.2020.9116198.M. Graf, G. A. G. Andrade and L. C. V. dos Santos, “EveCheck: An Event-Driven, Scalable Algorithm for Coherent Shared Memory Verification,” in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 2, pp. 683-696, Feb. 2023, doi: 10.1109/TCAD.2022.3178051.