


A codificação de vídeo é imprescindível para permitir o uso de vídeos digitais. Sem ela, vídeos com trinta ou sessenta quadros (frames) por segundo ocupariam um espaço gigantesco, inviabilizando o seu armazenamento em dispositivos móveis ou mesmo o compartilhamento de vídeos em tempo real, como acontece em videoconferências. Com base nessa perspectiva, codificadores atuam no sentido de modificar uma sequência de frames de modo a reduzir a quantidade de informação que deve ser armazenada, sobretudo ao explorar a diminuição de redundâncias entre frames. Os decodificadores, por sua vez, recebem a informação codificada e devem executar o caminho contrário ao codificador, descobrindo as informações necessárias para reconstrução e apresentação das imagens recebidas.
O modelo de codificador padrão é composto por diferentes etapas, conforme ilustra a Figura 1. Nele, o blocos do quadro original serão comparados com blocos de referência (preditos com base em informações de quadros passados ou do mesmo quadro). A diferença entre os dois blocos (resultado da subtração entre original e de referência) gera o que é chamado de resíduo, uma matriz com valores muito menores que do bloco original e que, portanto, gera um menor volume de informação para ser armazenado.
As redundâncias presentes nas imagens podem ser tanto espaciais (em um mesmo frame) como temporais (entre frames). Existem, portanto, dois tipos de predição: intra-quadros (em um mesmo quadro, para redundância espacial) e inter-quadros (entre quadros, para redundância temporal). Essa etapa de predição realiza a determinação dos blocos de referência. Em seguida, o resíduo passa por uma transformação, levando a sua informação para o domínio da frequência, de modo a possibilitar a filtragem apenas das componentes mais relevantas para a visão humana. Em seguida, tem-se a quantificação da informação e finalmente a codificação de entropia. Nessa codificação, dados que acontecem com maior frequência recebem codificações com menor número de bits, enquanto dados menos frequentes são mapeados para maiores conjuntos de bits, de modo a reduzir o bitstream gerado ao final da codificação.
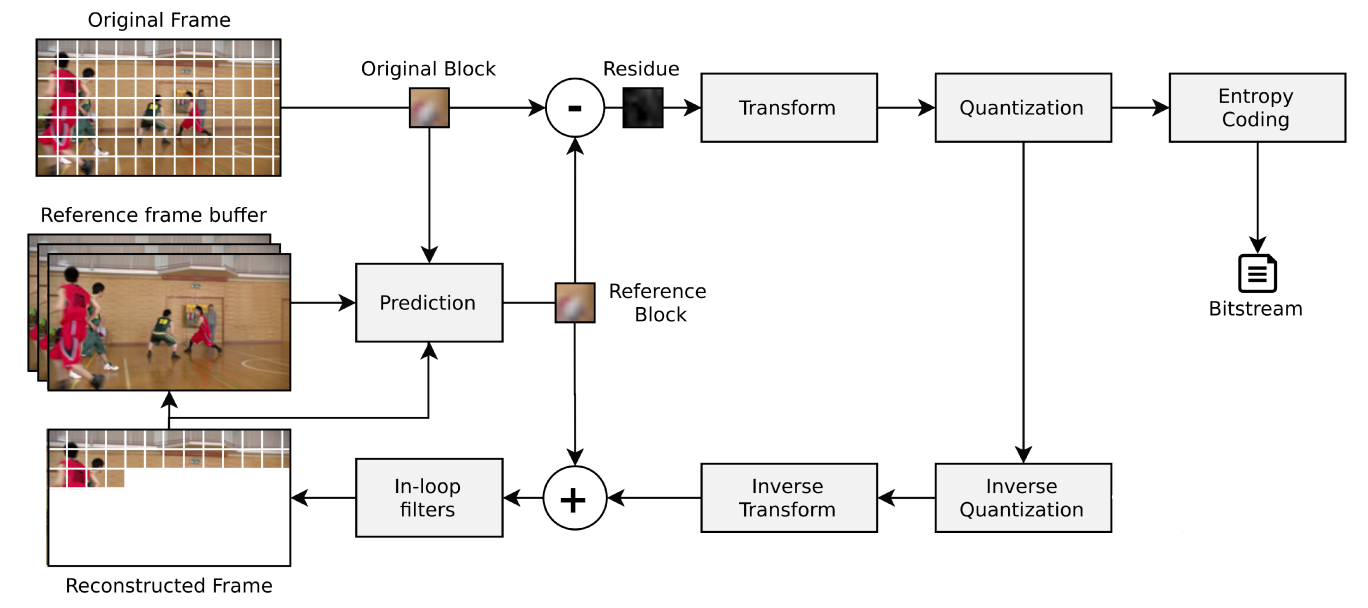
Figura 1: Representação das etapas da codificação de vídeo, adaptado de Richardson (2004) [1].
No ECL, desenvolvemos soluções em hardware para aplicações de codificação de vídeo, como arquiteturas para a Estimação de Movimento Fracionária (FME), uma das etapas mais custosas e que acontece durante a predição inter-quadros. Por meio de uma arquitetura dedicada, busca-se reduzir o consumo de energia do bloco, o que apresenta grande importância para a codificação de vídeo, visto a necessidade de processamento de imagem e vídeo em dispositivos móveis, movidos a bateria.
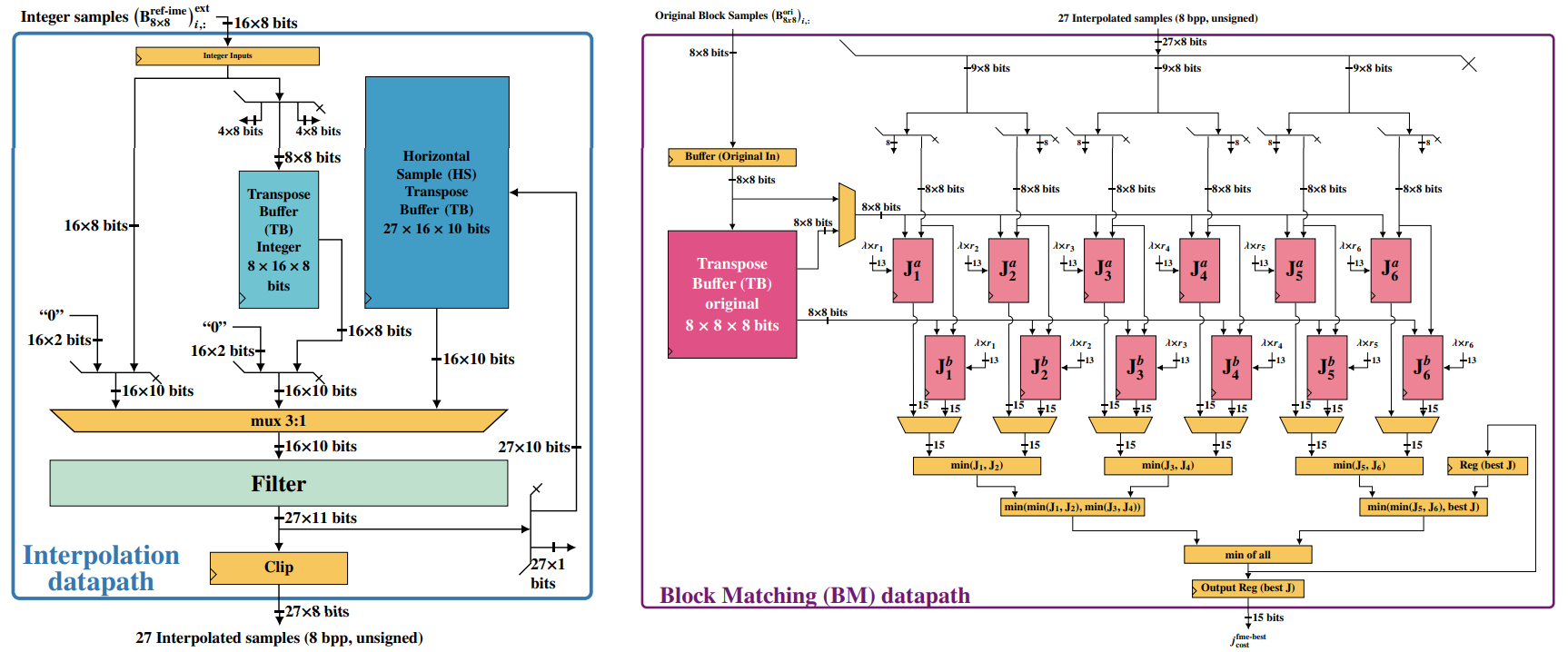
Figura 2: Representação dos módulos de interpolação e busca da arquitetura de FME desenvolvida no ECL.
Além da FME, também são realizadas no ECL pesquisas voltadas à Computação Aproximada (AxC), que consiste em uma abordagem para reduzir energia, área e atraso em arquiteturas de hardware. Avaliamos no ECL técnicas AxC em arquiteturas de filtro gaussiano para reduzir a potência e a área enquanto minimizamos a perda na qualidade da resolução. Ademais, desenvolvemos pesquisas que combinam métodos tradicionais de codificação de vídeo com Inteligência Artificial para melhorar a eficiência na codificação, além de estudar métodos de pós-processamento de vídeos, a fim de melhorar a experiência do usuário em diferentes plataformas.