Video coding is essential to make the use of digital videos possible. Without it, videos with thirty or sixty frames per second would take up a huge amount of space, making it impossible to store them on mobile devices or even share videos in real time, as it happens in videoconferences. Based on this perspective, encoders act on modifying a sequence of frames in order to reduce the amount of information that must be stored, especially when exploiting the minimization of redundancies between frames. The decoders, in turn, receive the encoded information and must follow the opposite path of the encoder, discovering the necessary information to reconstruct and present the images received.
The standard encoder model is composed of different steps, as illustrated in Figure 1. Inside the encoder, blocks from the original frame will be compared to reference blocks (predicted blocks based on information from past frames or the same frame). The difference between the two blocks (result of the subtraction between the original and the reference) generates what is called a residue, a matrix with much smaller values than the original block and which, therefore, generates a smaller volume of information to be stored.
The redundancies present in images can be both spatial (in the same frame) and temporal (between frames). There are, hence, two types of prediction: intra-frames (in the same frame, for spatial redundancy) and inter-frames (between frames, for temporal redundancy). This prediction step determines the reference blocks. The residue then undergoes a transformation, taking its information to the frequency domain, in order to enable filtering of only the most relevant frequency components for human vision. Next, there is the quantification of information and finally the coding of entropy. In this encoding, data that occurs more frequently receives encodings with a smaller number of bits, while less frequent data is mapped to larger sets of bits, in order to reduce the bitstream generated at the end of the encoding process.
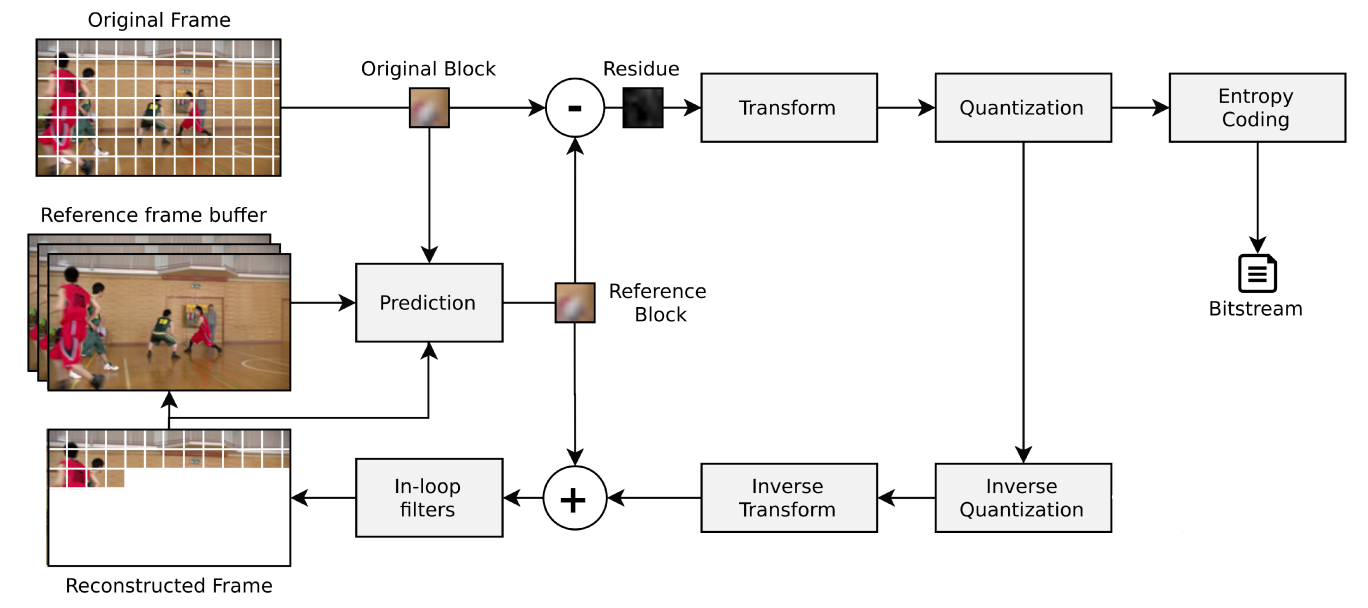
Figure 1: Representation of the video coding steps, adapted from Richardson (2004) [1].
At ECL, we develop hardware solutions for video coding applications, such as architectures for Fractional Motion Estimation (FME), one of the most computationally expensive steps that takes place during inter-frame prediction. Through a dedicated architecture, the aim is to reduce the block’s energy consumption, which is of great importance for video coding, given the need for image and video processing on battery-powered mobile devices.
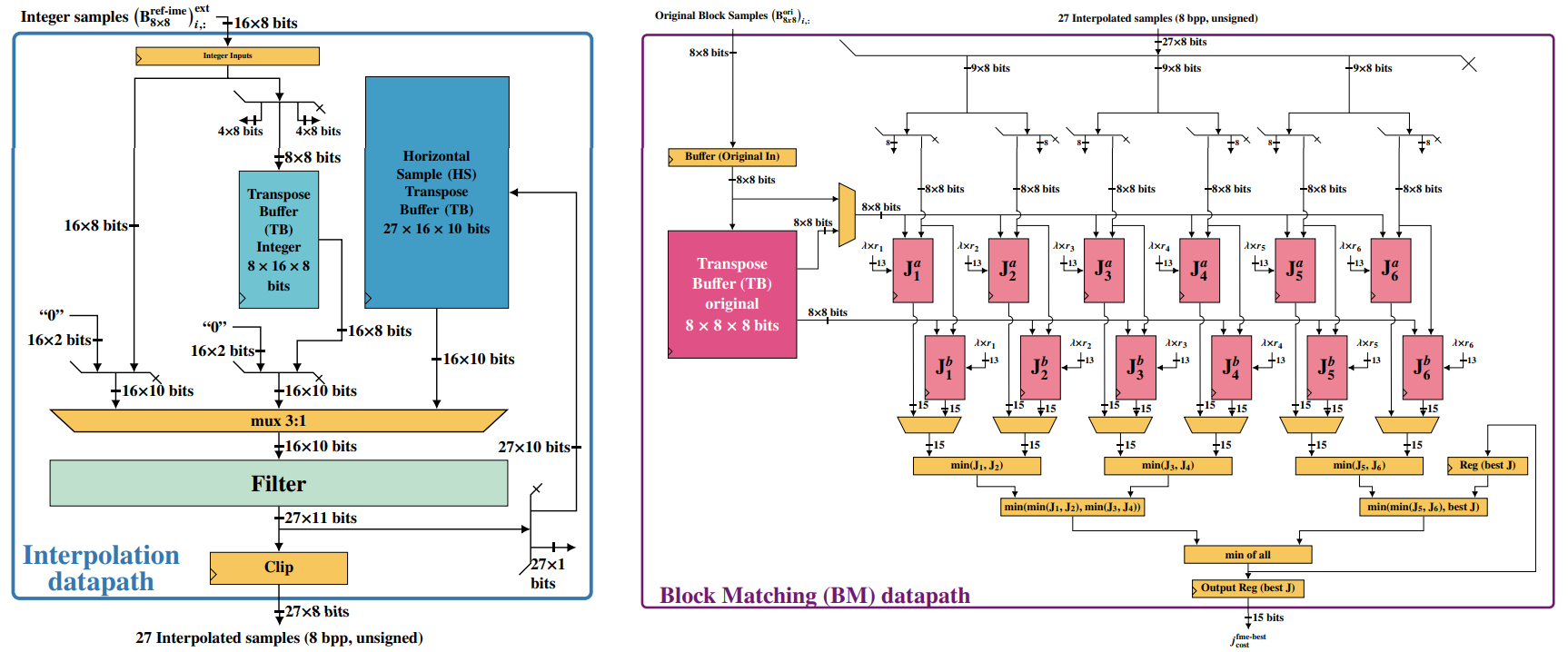
Figure 2: Representation of the interpolation and search modules of the FME architecture developed at ECL.
In addition to the FME, research focused on Approximate Computing (AxC) is also being developed at ECL, which consists of an approach to reduce energy, area and delay in hardware architectures. We evaluate AxC techniques on Gaussian filter architectures to reduce power and area while minimizing loss in resolution quality. Furthermore, we develop research that combines traditional video coding methods with Artificial Intelligence to improve coding efficiency, in addition to studying video post-processing methods, in order to improve the user experience on different platforms.
[1] RICHARDSON, I. E. G. H.264 and MPEG-4 video compression: video coding for next-generation multimedia. West Sussex, England: John Wiley & Sons Ltd, 2004. 206 p.